
ローカルLLMインストールサービス
ご購入いただいたシステムにローカルLLMが使用できるコンテナ(docker)環境をインストールします。
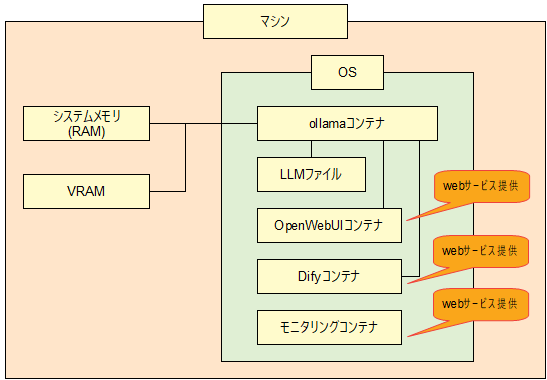
クラウドに依存せず、社内・所内で完結するプライベートなローカルLLM(オンプレミス生成AI)環境をDockerコンテナとしてインストールします。
セキュリティ面で優れたDockerのrootlessモードで環境構築します。
システム受取後すぐにローカルLLMをご利用いただけます。
サイズが異なる4つのLLMをプリインストールするため、お客様のシステムスペックに適したLLMを選択してご利用いただけます。
クラウドサービスと異なりローカルで完結するため、外部に公開できない情報を取り扱う際にも最適です。
デフォルトで3件の同時リクエストに対応しているため複数人での利用にも適しています。VRAM使用量が増えますが、同時リクエスト数は変更可能です。
- *同時リクエスト数を超えた後のリクエストは 実行中のリクエストが完了するまで待機状態となります。
- *リクエストを同じタイミングで多数行うとリクエストが滞留しコンテナの再起動が必要な場合があります。
お客様の用途にあわせたシステム構成でインストールサービスをご利用いただけます。一般的にはGPUのみでLLMを動かすイメージがあり、使用するLLMサイズより大きいVRAMのGPUを選択することが多いかと思います。しかし小さいLLMであればCPU+GPUでも十分な推論速度を出すことが可能です。VRAMが小さいGPUでも本インストールサービスにてLLMをお試しいただけます。
本サービスでは、ローカルLLM環境(Ollamaベース)に加え、ブラウザから簡単に利用できる「Open WebUI」や、ノーコード開発ツール「Dify」をあらかじめ構成に含めています。これにより、技術者だけでなく、業務部門のご担当者でもチャットボットの利用やプロトタイプ開発が行いやすく、社内のさまざまな業務でローカルLLMをご活用いただけます。
システム構成要件
- OS:Ubuntu 24.04 LTS (インストールにあたり、OSインストールディスクの60GB程度を使用します。)
- NVIDIA製GPU 1枚以上搭載
LLM
- Llama-3.1-Swallow-8B-Instruct-v0.5 (8B/Q4_K_M:4.92GB)
- gemma3:12b (12B/Q4_K_M:8.1GB)
- mistral-small3.2:24b (24B/Q4_K_M:15GB)
- ELYZA-Thinking-1.0-Qwen-32B-gguf (32B/Q5_K_M:23.3GB)
- *2025年10月時点(随時アップデート)
- *利用にあたっては各LLMの利用規約に準拠した運用をしてください。
フレームワーク: Ollama
Ollamaの利点はユーザビリティに優れている点です。特に「LLMの切り替え」「GPUのVRAMより大きいモデルの利用」について専門的な知識を必要とせず行うことができます。
<LLMの切り替え>
Open WebUI上のプルダウンメニューでLLMの切り替えが可能です。複数人が別々のモデルを使用するケースなどにも対応できます。
<GPUのVRAMより大きいモデルの利用>
GPUのVRAMより大きいサイズのLLMを動かす場合、VRAMにオフロードできない分をシステムメモリに自動的にオフロードする機能を有しているため推論速度の低下はありますがエラーになることなく動作します。
ユーザインタフェース: Open WebUI
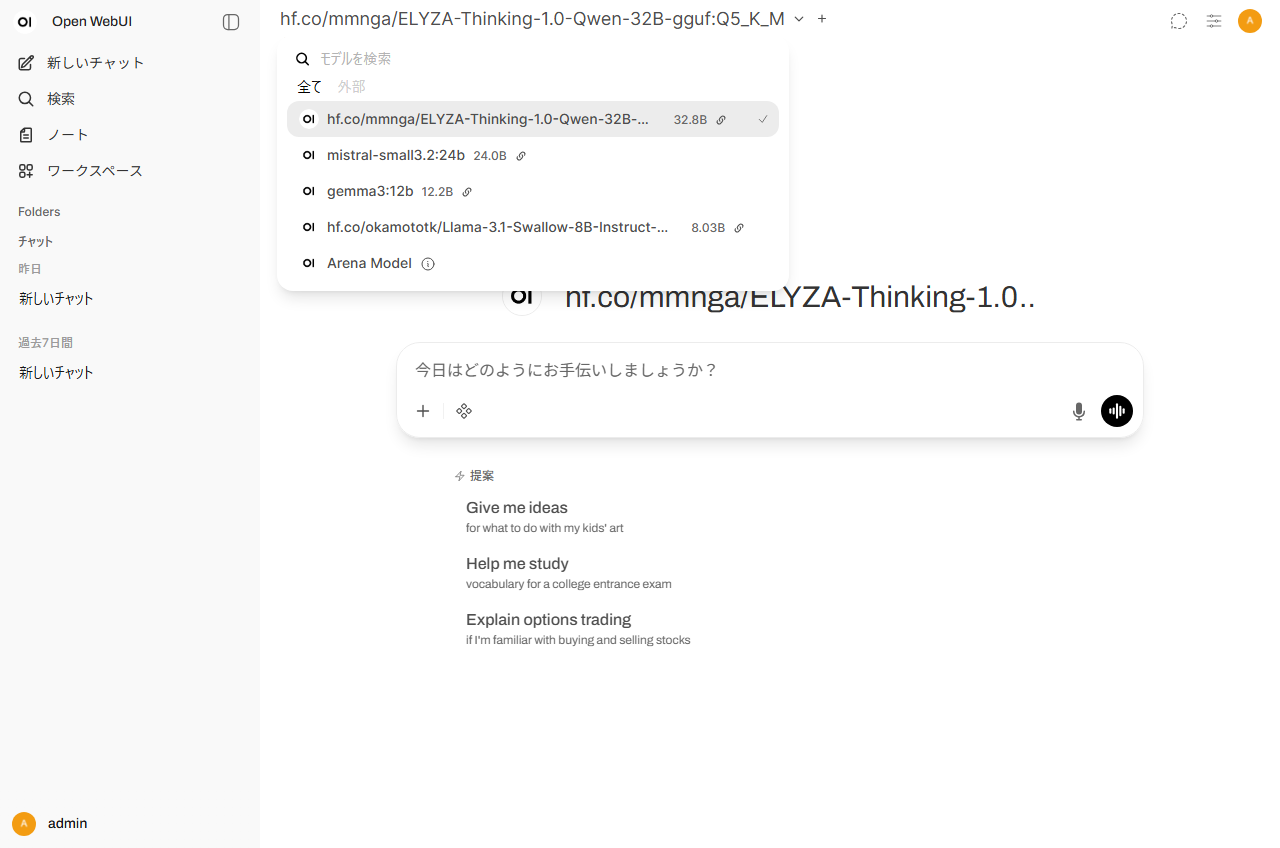
WEBベースの直感的なLLM利用が可能です。
<ファイル参照機能>
ファイルの記述内容要約など、ファイルを参照した質問が可能です。

<Web検索機能>
Web検索エンジンAPI(Google PSE,bing,Tavilyなど)と連携することで、リアルタイムでWEB情報を参照したLLMの回答が可能になります。
| Web検索機能無効 LLMが当社独自製品の情報を保有していないため回答できない。 |
 |
| Web検索機能有効 当社HPを参照することでLLMが回答可能になる。 |
 |
- *APIキーはお客様にて各サービスに登録・発行いただく必要がございます。
アプリケーション開発プラットフォーム: Dify
ノーコードでAIアプリケーションを開発・運用できるオープンソースのプラットフォームです。RAGを利用したチャットボットやワークフロー、AIエージェントなど様々なアプリケーションを簡単に作成することができます。
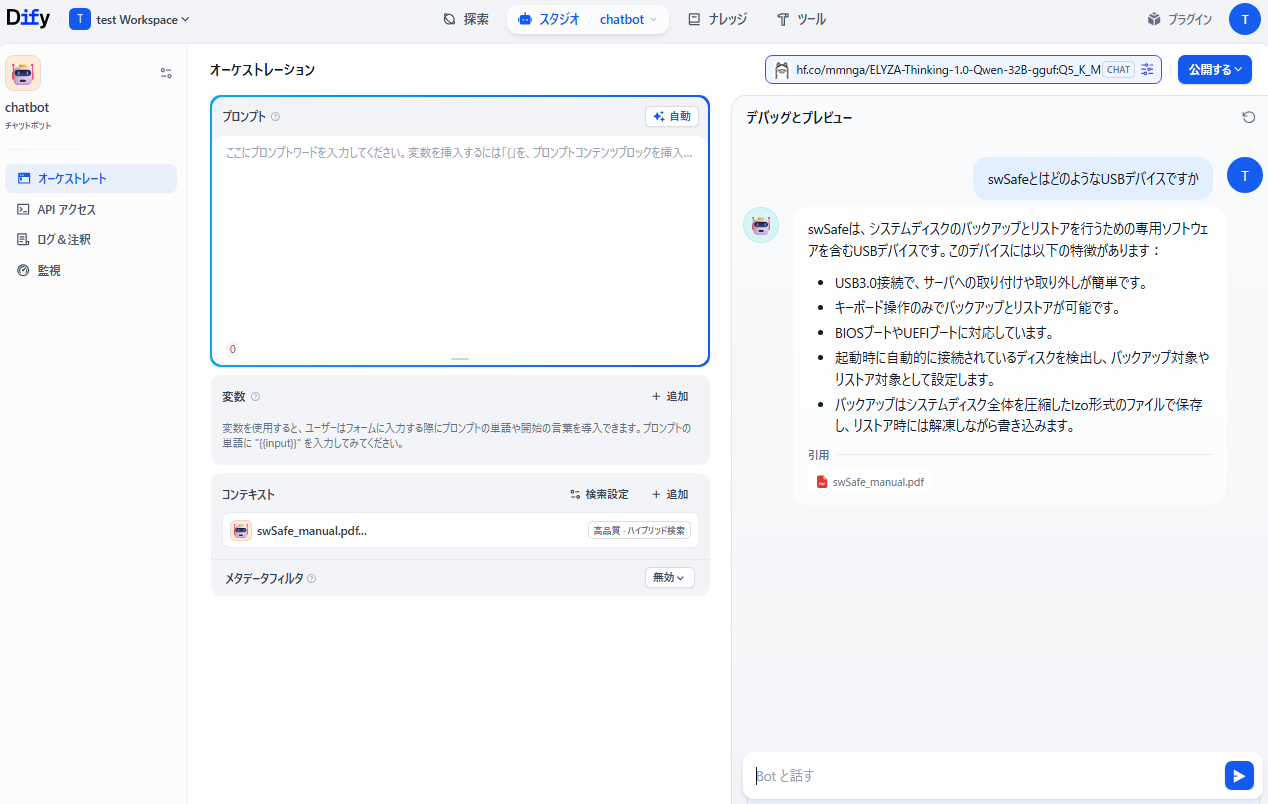
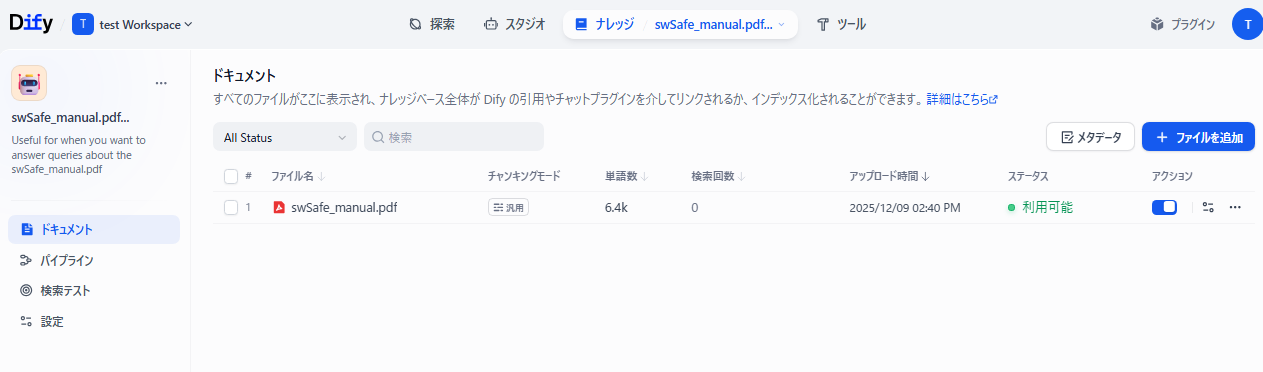
<RAGを利用したチャットボット>
チャットボットがナレッジベースに登録したファイルを参照して回答します。
 |
 |
<ワークフロー>
手作業で行う処理を自動化することが可能です。APIを利用した外部サービスとも連携できます。
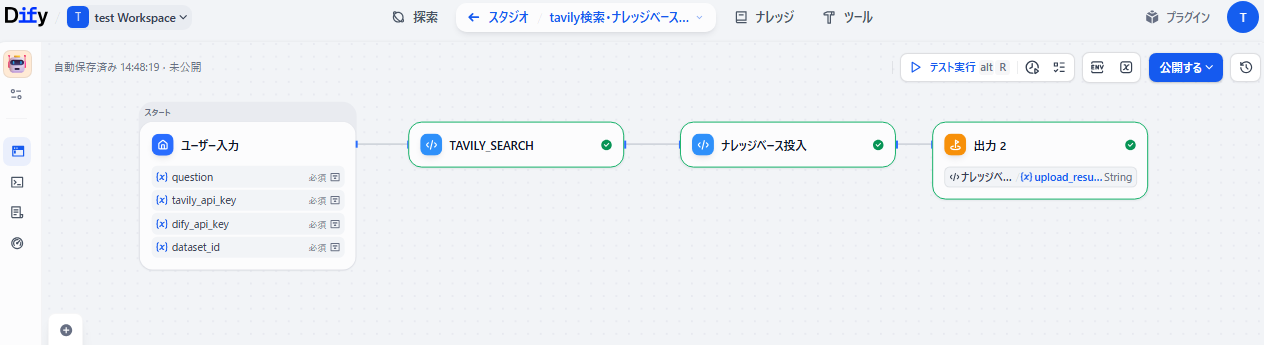 |
一元的なモニタリングサービス
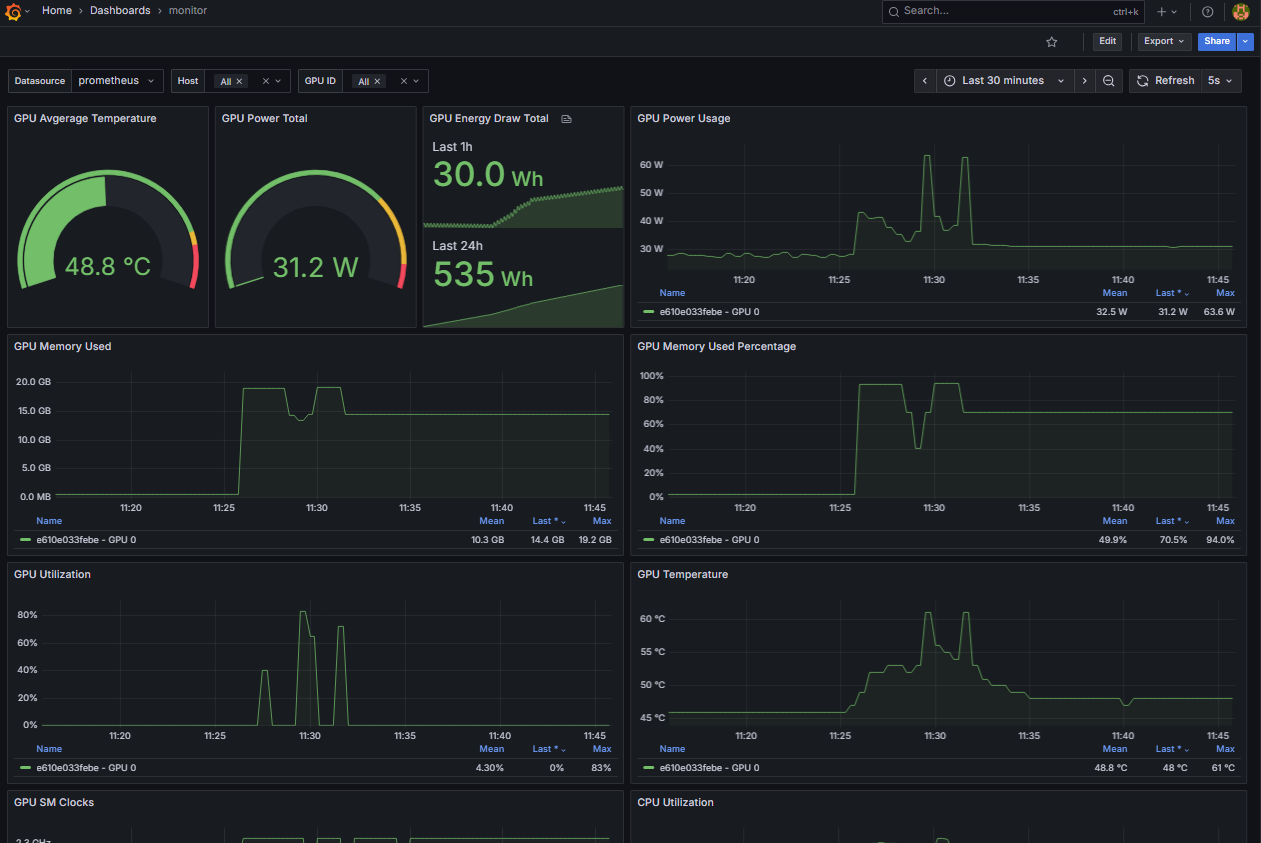
Grafanaを利用したモニタリングWEBサービスをインストールします。WEBサービスにアクセスするだけで以下の項目をモニタリング可能です。
- GPU Avgerage Temperature
- GPU Power Total
- GPU Energy Draw Total
- GPU Power Usage
- GPU Memory Used
- GPU Memory Used Percentage
- GPU Utilization
- GPU Temperature
- GPU SM Clocks
- CPU Utilization
- CPU Memory Used
- CPU Memory Used Percentage